Selected Publications

Learning to Fuse Sentences with Transformers for Summarization
In this paper, we explore the ability of Transformers to fuse sentences and propose novel algorithms to enhance their ability to perform sentence fusion by leveraging the knowledge of points of correspondence between sentences. Through extensive experiments, we investigate the effects of different design choices on Transformer’s performance. Our findings highlight the importance of modeling points of correspondence between sentences for effective sentence fusion.
In EMNLP,
2020
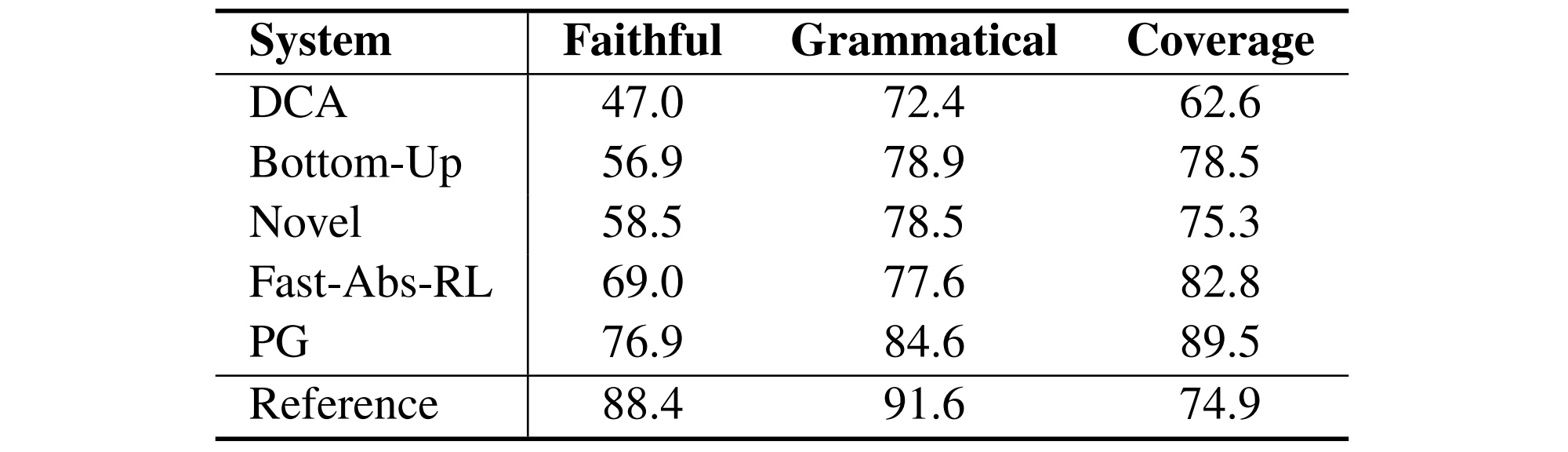
Analyzing Sentence Fusion in Abstractive Summarization
In this paper, we analyze the outputs of five state-of-the-art abstractive summarizers, focusing on summary sentences that are formed by sentence fusion. Our analysis reveals that system sentences are mostly grammatical, but often fail to remain faithful to the original article.
In EMNLP Summarization Workshop,
2019
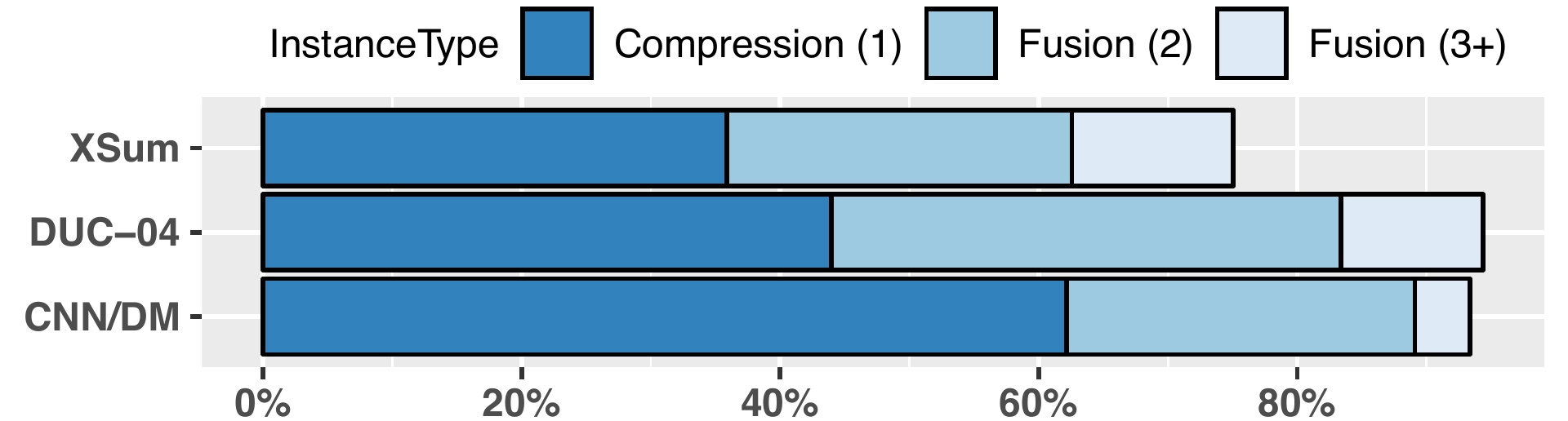
Scoring Sentence Singletons and Pairs for Abstractive Summarization
When writing a summary, humans tend to choose content from one or two sentences and merge them into a single summary sentence. Our proposed framework attempts to model human methodology by selecting either a single sentence or a pair of sentences, then compressing or fusing the sentence(s) to produce a summary sentence.
In ACL,
2019
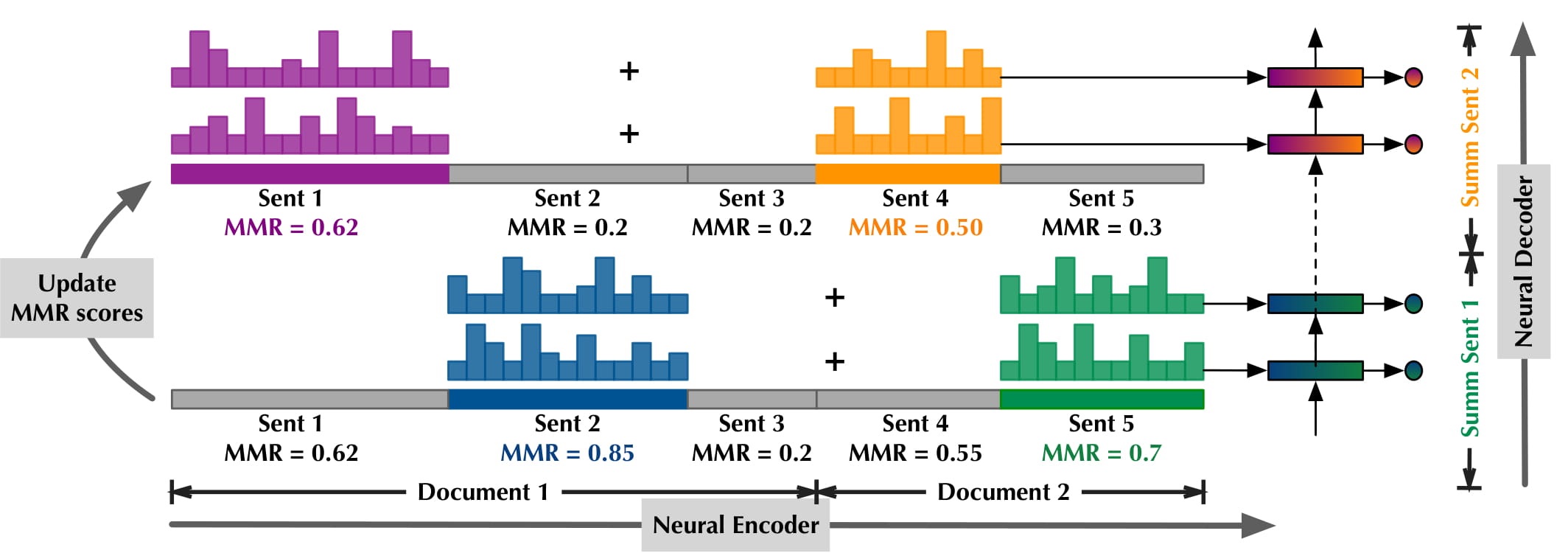
Adapting the Neural Encoder-Decoder Framework from Single to Multi-Document Summarization
In this paper we present an initial investigation into a novel adaptation method. It exploits the maximal marginal relevance method to select representative sentences from multi-document input, and an abstractive encoder-decoder model to fuse disparate sentences to an abstractive summary.
In EMNLP,
2018